

Leveraging Apache Iceberg Catalogs
Leveraging Apache Iceberg Catalogs
Released: May 29, 2025
Duration: 21m 39s | .MP4 1920x1080, 30 fps(r) | AAC, 48000 Hz, 2ch | 52 MB
Genre: eLearning | Language: English
Released: May 29, 2025
Duration: 21m 39s | .MP4 1920x1080, 30 fps(r) | AAC, 48000 Hz, 2ch | 52 MB
Genre: eLearning | Language: English
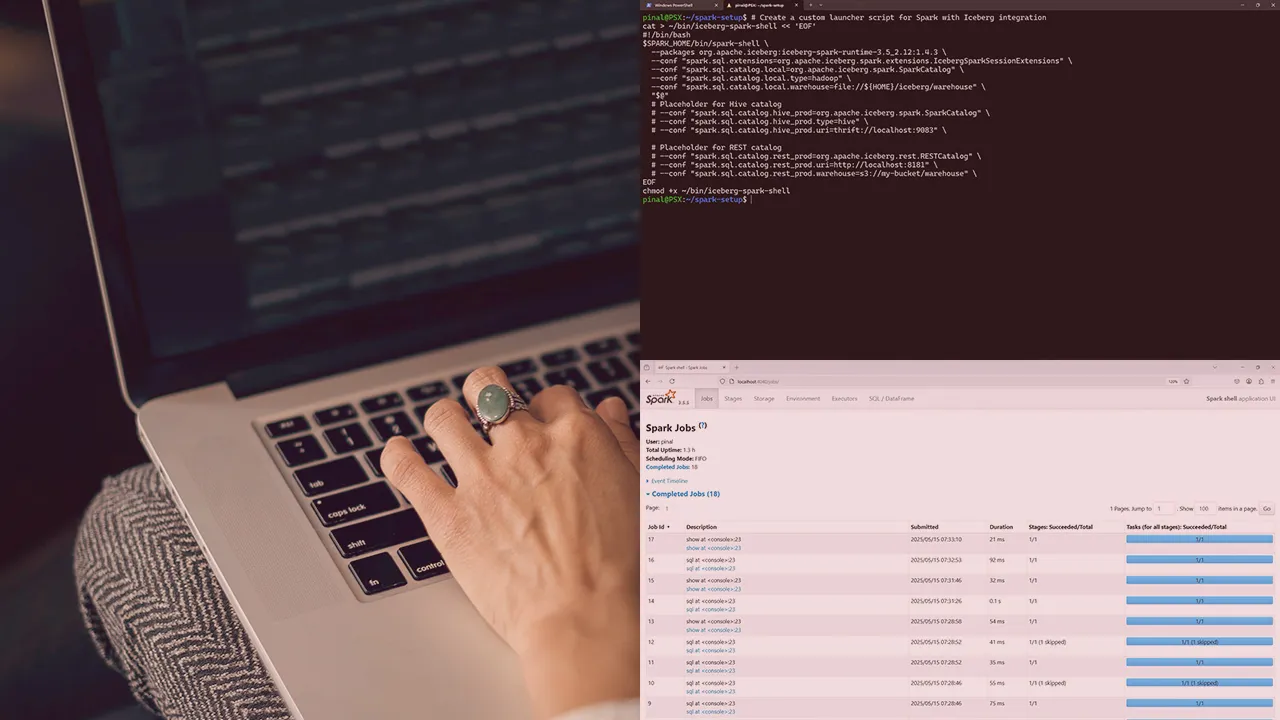
Manage and explore metadata using Apache Iceberg catalogs. This course will teach you how to configure different catalog types, register and manage tables, and perform table operations using SQL and CLI for consistent, engine-agnostic data access.
What you'll learn
Managing metadata across modern data lake engines can quickly become complex and error-prone without a consistent, centralized catalog layer. Inconsistent schemas, duplicated logic, and incompatible engine behavior often lead to fragile pipelines and operational overhead. In this course, Leveraging Apache Iceberg Catalogs, you’ll gain the ability to configure and use Iceberg catalogs to manage table metadata across Spark, and to use other engines in reliable, engine-agnostic ways. First, you’ll explore how Iceberg catalogs abstract metadata and enables cross-engine interoperability, starting with local catalog setups and a comparison of JDBC, Hive, and REST implementations. Next, you’ll discover how to create and register Iceberg tables using SQL and CLI, and understand how metadata is stored and tracked within the catalog. Finally, you’ll learn how to explore catalog contents, inspect table properties, and perform key operations like renaming and dropping tables—all while observing how the catalog reflects and manages these changes. When you’re finished with this course, you’ll have the skills and knowledge of Apache Iceberg catalogs needed to build flexible, interoperable data platforms that scale across tools and teams.
More Info