Conceptualizing the Processing Model for Apache Spark Structured Streaming
Conceptualizing the Processing Model for Apache Spark Structured Streaming
MP4 | Video: AVC 1280x720 | Audio: AAC 44KHz 2ch | Duration: 3 Hours | 329 MB
Genre: eLearning | Language: English
MP4 | Video: AVC 1280x720 | Audio: AAC 44KHz 2ch | Duration: 3 Hours | 329 MB
Genre: eLearning | Language: English
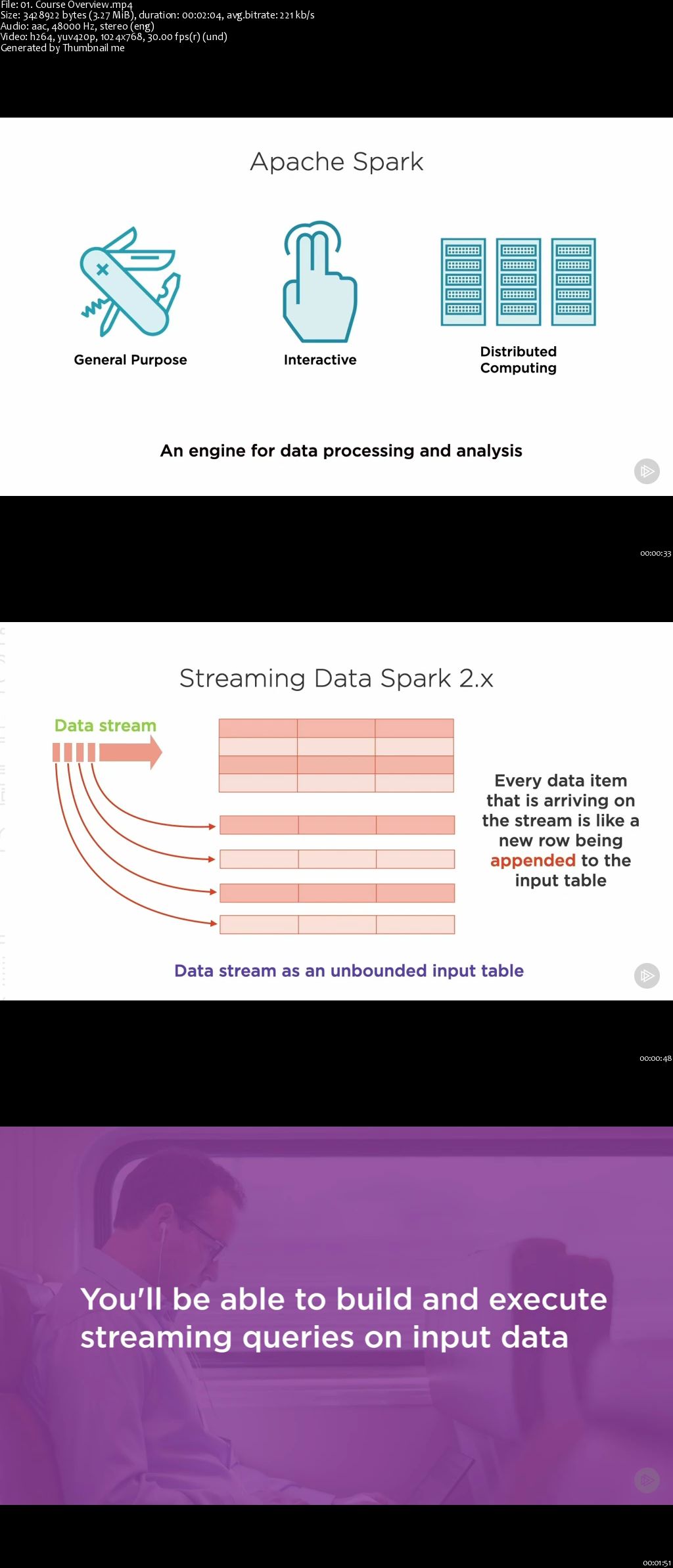
Much real-world data is available in streams; from self-driving car sensors to weather monitors. Apache Spark 2 is a strong analytics engine with first-class support for streaming operations using micro-batch and continuous processing.
Structured Streaming in Spark 2 is a unified model that treats batch as a prefix of stream. This allows Spark to perform the same operations on streaming data as on batch data, and Spark takes care of the details involved in incrementalizing the batch operation to work on streams.
In this course, Conceptualizing the Processing Model for Apache Spark Structured Streaming, you will use the DataFrame API as well as Spark SQL to run queries on streaming sources and write results out to data sinks.
First, you will be introduced to streaming DataFrames in Spark 2 and understand how structured streaming in Spark 2 is different from Spark Streaming available in earlier versions of Spark. You will also get a high level understanding of how Spark’s architecture works, and the role of drivers, workers, executors, and tasks.
Next, you will execute queries on streaming data from a socket source as well as a file system source. You will perform basic operations on streaming data using Data frames and register your data as a temporary view to run SQL queries on input streams. You will explore the append, complete, and update modes to write data out to sinks. You will then understand how scheduling and checkpointing works in Spark and explore the differences between the micro-batch mode of execution and the new experimental continuous processing mode that Spark offers.
Finally, you will discuss the Tungsten engine optimizations which make Spark 2 so much faster than Spark 1, and discuss the stages of optimization in the Catalyst optimizer which works with SQL queries.
At the end of this course, you will be able to build and execute streaming queries on input data, write these out to reliable storage using different output modes, and checkpoint your streaming applications for fault tolerance and recovery.

Conceptualizing the Processing Model for Apache Spark Structured Streaming