PostgreSQL High Performance Tuning Guide

PostgreSQL High Performance Tuning Guide
.MP4, AVC, 1280x720, 30 fps | English, AAC, 2 Ch | 2h 40m | 572 MB
Instructor: Lucian Oprea
.MP4, AVC, 1280x720, 30 fps | English, AAC, 2 Ch | 2h 40m | 572 MB
Instructor: Lucian Oprea
Tips for Tuning PostgreSQL like a Pro | Learn how to prevent Postgres performance problems
What you'll learn
- The theory of PostgreSQL architecture and how it works under-the-hood
- Understand how to set shared_buffers for better performance
- Learn how to configure Vacuum to keep the database clean and fast
- How to use an Index efficiently
- Practice Index optimization strategies
- How to make sense of Statistics
- Master how to spot Query Problems
- Practice Query optimizations techniques
- Fundamental Concepts for Scaling and Replication in PostgreSQL
Requirements
- You need access to a Windows/Mac/Linux PC with 10GB of free disk space
- Basic familiarity with database objects such as tables and indexes is expected
- Some familiarity with Linux will be helpful
Description
PostgreSQL is one of the most powerful and easy-to-use database management systems. It has strong support from the community and is being actively developed with a new release every year.
PostgreSQL supports the most advanced features included in SQL standards. It also provides NoSQL capabilities and very rich data types and extensions. All of this makes PostgreSQL a very attractive solution in software systems.
However, getting the best performance from it has not been an easy subject to tackle. You need just the right combination of rules of thumb to get started, proper testing, solid monitoring, and maintenance to keep your system running well, and hints for add-on tools to add the features the core database doesn't try to handle on its own.
This Udemy course is structured to give you both the theoretical and practical aspects to implement a High-Performance Postgres. It will help you build dynamic database solutions for enterprise applications using one of the latest releases of PostgreSQL.
You'll examine all the advanced aspects of PostgreSQL in detail, including logical replication, database clusters, performance tuning, and monitoring. You will also work with the PostgreSQL optimizer, configure Postgres for high speed by looking at transactions, locking, indexes, and optimizing queries.
You are expected to have some exposure to databases. Basic familiarity with database objects such as tables and indexes is expected. You will find this Udemy course really useful if you have no or a little exposure to PostgreSQL. If you have been working with PostgreSQL for a few years, you should still find a few useful commands that you were not aware of or a couple of optimization approaches you have not tried. You will also gain more insight into how the database works.
PostgreSQL Performance Tuning Online Course Curriculum:
Understanding PostgreSQL Server Architecture
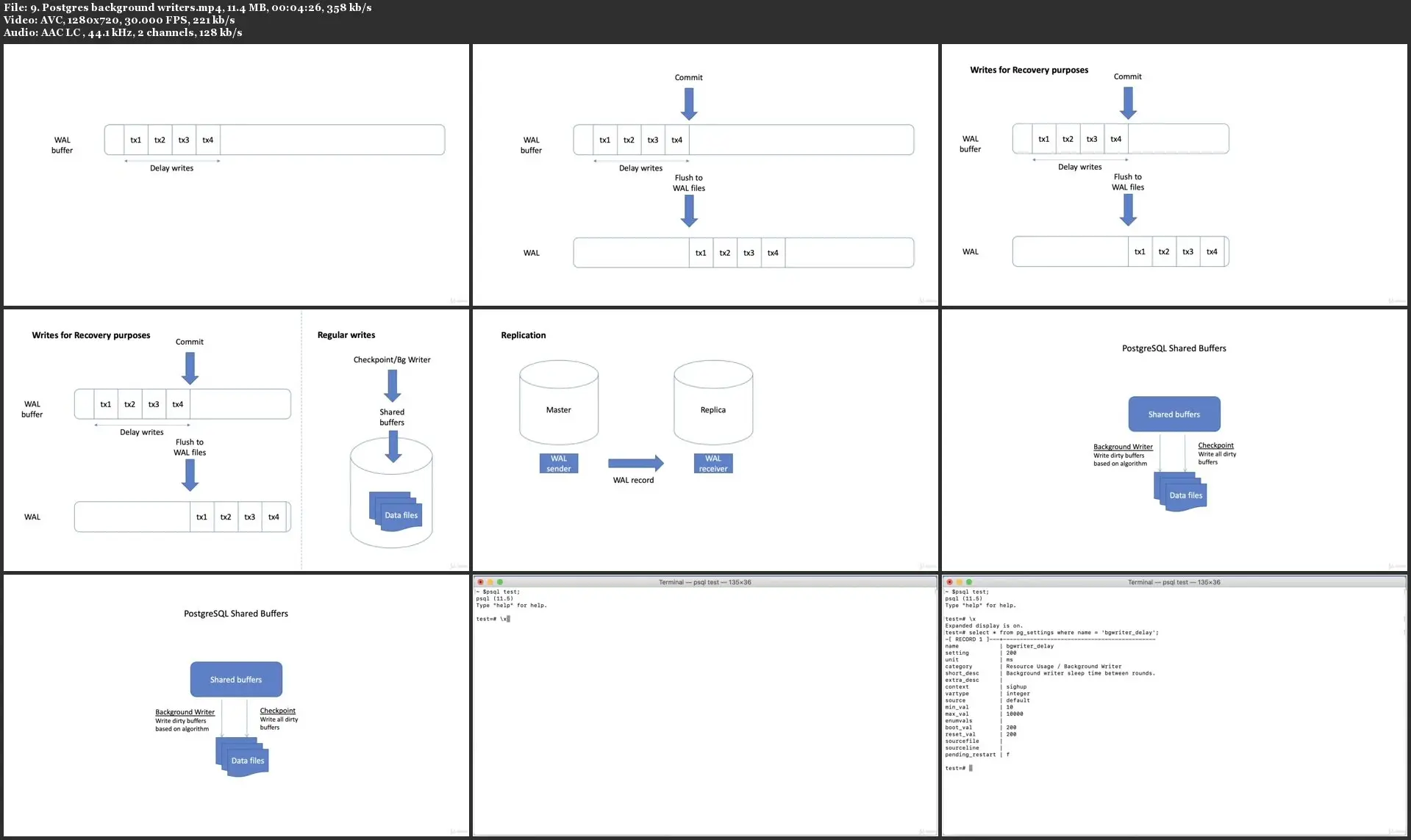
- In this section, we will explore the PostgreSQL Architecture.
- Shared Buffers work in cooperation with the operating system cache, rather than replacing it. These caches improve performance by reducing the physical I/O necessary.
- Why do we need to set Checkpoints carefully to limit crash recovery time, while not impacting the rest of the system's performance?
- This section will give you all an introduction to why we need the WAL Writer and also the Background Writer.
- See the stages that the Query Processor has to pass in order to obtain the results.
- The utility Subsystem provides ways to maintain the database, such as claiming storage, updating statistics and logging.
Configuring Vacuum for Performance
- We will understand why any time we do an UPDATE or DELETE, we will leave a dead row behind (and potentially a dead index entry) that needs to be cleaned up later by some form of vacuum.
- We will learn that when tables grow very large because of excessive dead tuples then performance will tend to decrease. Therefore the VACUUM process should never be avoided.
- This section explains why it's better to have a steady low-intensity vacuum work, using the autovacuum feature of the database, instead of disabling that feature and having to do that cleanup in larger blocks.
How to use an Index efficiently
- Understand that adding an index increase overhead every time you add or change rows in a table. Each index needs to satisfy enough queries to justify how much it costs to maintain.
- In this section, we'll explain why the execution plan of a query depends on the data inside the table. If the data has low carnality, PostgreSQL will most probably ignore the index
- In this section we'll learn why an index is only useful if it is selective; it can be used to only return a small portion of the rows in a table.
- In this section, we will explore how to use bitmap scans effectively
Index Optimization Tips
- On top of just using indexes, it is also possible to implement custom strategies for your particular application to speed things up
- How to be able to answer queries by only using the data in an index using covering indexes.
- This section covers why defining indexes on foreign keys it's a good practice.
- In this section, we will explore partial indexes and how small, efficient index can be enjoyed.
- Indexes can require periodic rebuilding to return them to optimum performance, and clustering the underlying data against the index order can also help improve their speed for queries.
- We'll explain when it's useful to modify the fill factor parameter of a table.
- In this section, we will see in which cases it's better to use a combined index vs multiple independent indexes.
Making Use of Statistics
- In this section, you'll explore statistics that can help you find and sort the queries that are responsible for most of the load on the system.
- PostgreSQL offers a large set of statistics. In this section, we'll make it easier to take advantage of their insights.
- We'll get to see the fastest way to detect missing indexes but we'll also explore when it's necessary to drop indexes.
Spotting Query Problems
- We'll explain how to read query plans and understand how each of the underlying node types works.
- We'll get to see how queries are executed as a series of nodes that each do a small task, such as fetching data aggregation or sorting.
- We'll explore portions of the query that actually had the longest execution time, and see if they had an appropriate matching cost.
- The variation between estimated and actual rows can cause major planning issues. We'll explore what we can do in such cases.
Query Optimizations Tips
- We'll see why it's important to first question the semantic correctness of a statement before attacking the performance problem
- We'll understand why we should avoid SELECT *, ORDER BY and DISTINCT unless we really need them and there is no other way
- We'll explore PostgreSQL features such as CASE syntax and parallel queries to reduce time execution for queries
How to set shared_buffers for better performance
- We will see that the PostgreSQL allocation for the default shared_buffers is extremely low and we need to increase it to allow proper shared memory size for the database.
- We will cover how shared_buffers works in cooperation with operating system cache, rather than replacing it and we should size it as only a moderate percentage of total RAM.
- We will understand that if we want to do better than allocating a percentage to the shared_buffers relative to the OS cache, we need to analyze the buffers cache content
Scaling and Replication
- We'll see how replication can also be used to improve the performance of a software system by making it possible to distribute the load on several database servers.
- In some cases, the functionality of replication provided by PostgreSQL isn't enough. There are third-party solutions that work around PostgreSQL, providing extra features, such as Pgpool-II which can work as a load balancer and Postgres-XL which implements a multi-server distributed database solution that can operate very large amounts of data and handle a huge load.
Who this course is for:
- Database Administrators
- Software Developers interested in advanced database internals that impact application design and performance
- Everyone interested in building better PostgreSQL applications
PostgreSQL High Performance Tuning Guide