Scaling AI Models with Mixture of Experts (MOE): Design Principles and Real-World Applications
Scaling AI Models with Mixture of Experts (MOE): Design Principles and Real-World Applications
.MP4, AVC, 1280x720, 30 fps | English, AAC, 2 Ch | 1h 55m | 232 MB
Instructor: Vaibhava Lakshmi Ravideshik
.MP4, AVC, 1280x720, 30 fps | English, AAC, 2 Ch | 1h 55m | 232 MB
Instructor: Vaibhava Lakshmi Ravideshik
Mixture of Experts (MoE) is a cutting-edge neural network architecture that enables efficient model scaling by routing inputs through a small subset of expert subnetworks. In this course, instructor Vaibhava Lakshmi Ravideshik explores the inner workings of MoE, from its core components to advanced routing strategies like top-k gating. The course balances theoretical understanding with hands-on coding using PyTorch to implement a simplified MoE layer. Along the way, you’ll also get a chance to review real-world applications of MoE in state-of-the-art models like GPT-4 and Mixtral.
Learning objectives
- Define the structure and core components of a Mixture of Experts (MoE) model, including experts and gating mechanisms.
- Distinguish between various MoE architectures (token-wise, layer-wise, hierarchical) and gating strategies (soft, hard, and top-k).
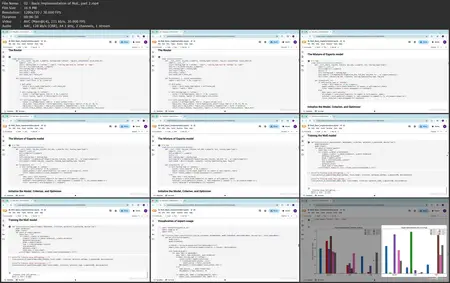
- Implement a basic MoE layer in PyTorch and integrate it within a transformer-based architecture.
- Analyze trade-offs in MoE design and apply them in scaling large language models efficiently.
- Identify real-world applications of MoE in large-scale AI models such as GShard, Switch Transformer, and Mixtral.
Scaling AI Models with Mixture of Experts (MOE): Design Principles and Real-World Applications